Catching the Trade Winds : How a Security analysis harness got me a CVE.
Introduction
Recently I developed a security analysis harness which I used to find vulnerability in Github repositories. My main goal was to get a CVE without wasting much resources and time. And to make it more challenging I thought of creating an AI assisted framework which will automate the whole process (Since I’m leaning towards AI sector and want to learn more about AI, I thought it will be a fun project).
Beginning
And so, I began reading blogs about developing automation frameworks. Also thanks to my team 0bscuri7y who regularly shares security blogs and insights, I came across one of the best blogs:
In summary these blogs just explain that it’s much better to divide the security repository into smaller parts (chunks) and then perform security assessment on the chunks. Doing so generally helps LLMs focus on the most relevant code, resulting in more accurate analysis and higher quality findings. The underlying reason is that modern LLMs often struggle to utilize long contexts effectively, especially when critical information is buried in the middle of a prompt. If you wish to know about it in detail you can feel free to read :
Key Line - “…prompting language models with longer input contexts is a trade-off— providing the language model with more information may help it perform the downstream task, but it also increases the amount of content that the model must reason over, potentially decreasing accuracy.”
Methodology
This is the Methodology I used :
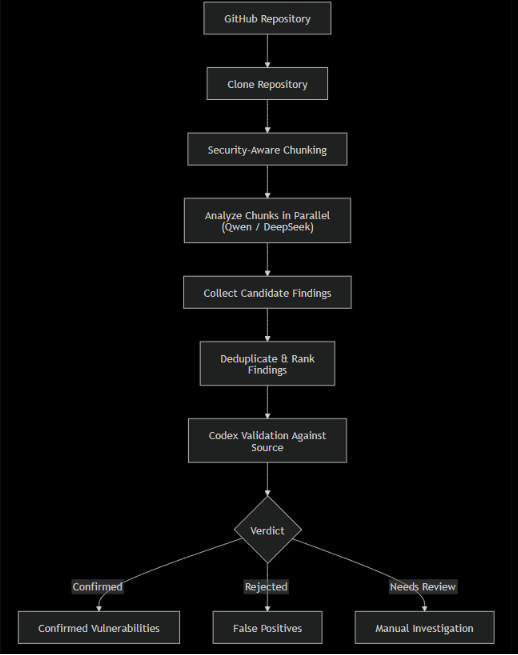
And it is indeed quite effective.
It includes :
- Dividing repo into multiple chunks (mainly each chunk consisted of 8000-15000 worth of tokens code)
- Using an open weight model to find vulnerabilities in those chunks (since there’s a lot of content, using a SOTA closed weight model is going to cost you a lot that’s why I prefer a cheaper model for scanning).
- This step consists of aggregation and deduplication.
- Now codex checks all the candidate generated by open weight model and validates whether the security finding actually exists or not.
- All the confirmed findings are then collected in a md file, which I use to create a PoC and test it manually.
Conclusion
This methodology helped me in getting a CVE :
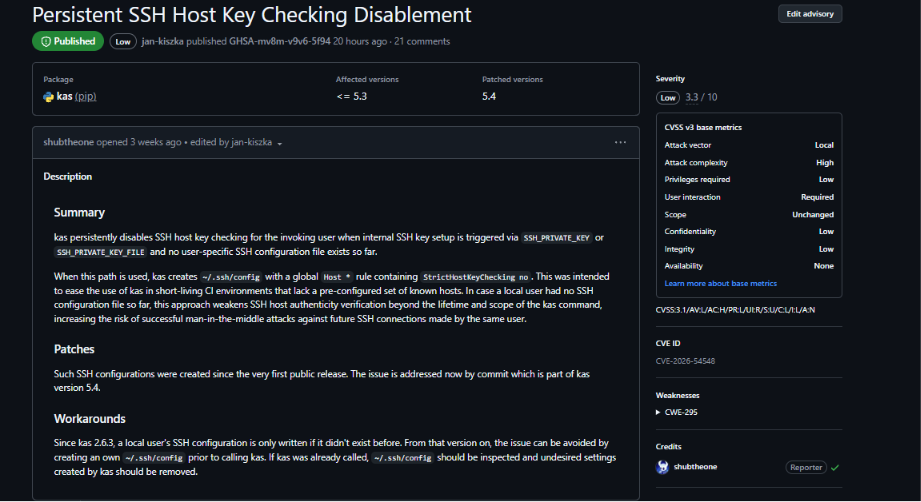
Sadly the finding wasn’t that interesting but I think it was a fun project. I learned alot.
Thank you guys, see ya in next blog :)